[Smart Beta] Chapter 4. Low Risk Factor : 저위험 팩터 (2)
Low Risk Factor 저위험 팩터
[SMART BETA] Low Risk Factor 저위험 팩터 (2)
BackTesting
실제 국내 시장에서의 저변동성 효과의 확인을 위해서 백테스트를 활용하여 검증한다.
Methodology 활용 데이터 : KOSPI200에서 2000년부터 2016년까지의 월별 데이터가 존재하는 종목들을 사용
Step 1. 현재 시점 t에서 과거 n개월을 기준으로 수익률의 표준편차를 계산
Step 2. 계산된 표준편차가 가장 작은 종목부터 가장 큰 종목까지의 순서를 활용하여 각 N개의 포트폴리오에 포함될 개별자산을 선정
Step 3. 향후 투자기간 k에 대하여 t+k 시점까지 투자할 포트폴리오 N개를 위 방법을 통하여 구성
Step 4. 위 작업을 k 기간마다 반복하여 rebalancing
Step 5. 구성된 포트폴리오의 투자 수익률을 그래프를 통해 확인한다.
1. Data
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from matplotlib.pyplot import rc
rc('font',family='Malgun Gothic')
data = pd.read_excel("ch4_data.xlsx", sheetname='Sheet4', index_col=0)/100
data.tail()
| CJ | CJ대한통운 | DB손해보험 | DB하이텍 | GS건설 | JW중외제약 | KCC | LG | LG상사 | LS | ... | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2016-08-31 | -0.0474 | 0.0025 | 0.0630 | -0.0421 | 0.0017 | 0.2474 | 0.0456 | 0.0378 | -0.0878 | 0.1801 | ... |
| 2016-09-30 | -0.0262 | 0.0721 | 0.0104 | 0.0440 | 0.0209 | 0.2080 | -0.0412 | -0.0182 | 0.0496 | -0.0747 | ... |
| 2016-10-31 | -0.0618 | -0.0673 | 0.0425 | -0.0421 | -0.0869 | -0.4351 | 0.0228 | -0.0526 | -0.2020 | -0.0567 | ... |
| 2016-11-30 | 0.0057 | -0.0846 | 0.0267 | -0.0880 | -0.1175 | -0.0061 | -0.0791 | -0.0783 | 0.0826 | 0.1093 | ... |
| 2016-12-31 | 0.0655 | -0.0272 | -0.1438 | 0.0225 | 0.1205 | 0.0987 | -0.0349 | 0.0619 | -0.0299 | -0.0263 | ... |
5 rows × 91 columns
다음과 같이 기간상의 문제나 오류가 없는 KOSPI200의 개별 종목들의 데이터를 활용합니다.
2. Slicing tools
def how_many_times(data, times, rebal = 1):
#repet_times = len(data)-times
start_period = np.array(list(map(lambda x: x, range(len(data.index)-times+1))))
end_period = np.array(list(map(lambda x: x+times-1, range(len(data.index)-times+1))))
period_list = list(map(lambda x: x*rebal, range(int(np.ceil(len(start_period)/rebal)))))
return start_period[period_list], end_period[period_list]
각 데이터에 대한 과거 수익률을 얻기 위해서 rebalancing 시기마다의 backtesting 기간의 데이터를 slicing하기 위하여 인덱스의 순서를 뽑아주는 function을 정의합니다.
start_period, end_period = how_many_times(data, 60, 3)
end_period
array([ 59, 62, 65, 68, 71, 74, 77, 80, 83, 86, 89, 92, 95,
98, 101, 104, 107, 110, 113, 116, 119, 122, 125, 128, 131, 134,
137, 140, 143, 146, 149, 152, 155, 158, 161, 164, 167, 170, 173,
176, 179, 182, 185, 188, 191, 194, 197, 200, 203, 206, 209, 212,
215, 218, 221, 224, 227, 230, 233, 236, 239, 242, 245, 248, 251,
254, 257, 260, 263])
다음과 같이 데이터에서 60개월의 데이터를 이용하여 backtesting을 하고 매 3개월 마다 이 작업을 반복하여 rebalancing을 하는 경우를 상정한 예시에서는 data의 index를 추출하기 위한 리스트를 반환받습니다.
def how_many_stocks(data, many):
N = len(data.columns)
num_of_stock = int(N/many)
initial = list(map(lambda many: (num_of_stock*many), range(many)))
end = list(map(lambda many: num_of_stock+(num_of_stock*many), range(many)))
if end[-1] != N:
end[-1] = N-1
return initial, end
위에서 기간을 slicing 하기 위하여 function을 구성하였던 것처럼 각 포트폴리오에 편입될 개별 주식들을 slicing 하기 위한 function을 구성합니다.
initial, end = how_many_stocks(data, 5)
end
[18, 36, 54, 72, 90]
위에서처럼 5개의 포트폴리오를 구성한다고 한다면 slicing 하기 위해 얻을 수 있는 column index의 순서 리스트를 다음과 반환받습니다.
3. Calculation tools
첫 번째, backtesting에 활용할 수익률과 이후 투자기간에 대한 데이터를 각각 DataFrame의 형태를 통하여 input data로 받으면 N개의 포트폴리오의 구성기준(표준편차)에 따라서 각 포트폴리오의 편입될 자산들만을 포함한 DataFrame N개를 리스트의 형태로 반환합니다.
def df_return(data, data2, initial, end):
split_std = np.std(data)
std_sort = split_std.sort_values()
std_index = list(std_sort.index)
df_list = list()
for j in range(len(end)):
stock_split_list = std_index[initial[j]:end[j]]
stock_split_data = data2[stock_split_list]
df_list.append(stock_split_data)
return df_list
두 번째, 각 포트폴리오에 속하는 자산들만을 포함한 DataFrame 리스트를 input으로 입력받아 해당 포트폴리오의 구성방식(동일가중)의 형태로 수익률을 계산해 각 포트폴리오의 해당 투자기간동안의 수익률을 반환하는 function을 구성합니다.
def portfolio_generater(list_data, method = 'eq'):
portfolio_df = pd.DataFrame()
for i in range(len(list_data)):
ret_data = list_data[i]+1
portfolio = np.mean(np.cumprod(ret_data), axis=1)
num_port = 'portfolio'+str(i+1)
portfolio_df.loc[:,num_port] = portfolio[-1:]
return portfolio_df
4. Backtesting function
2번 slicing tools, 3번 calculation tools에서 구성한 함수를 통하여 backtesting을 하는 함수를 구성합니다.
def period_split_std(data, times, rebal, many):
start_period, end_period = how_many_times(data, times, rebal)
initial, end = how_many_stocks(data, many)
total_list = list()
for i in range(len(start_period)-1):
data_split = data.ix[data.index[start_period[i]]:data.index[end_period[i]]]
data_split_plus = data.ix[data.index[start_period[i+1]]:data.index[end_period[i+1]]]
data_split_2 = data_split_plus.ix[data_split_plus.index[-rebal]:,]
list_data = df_return(data_split, data_split_2, initial, end)
n_period_port = portfolio_generater(list_data, rebal)
total_list.append(n_period_port)
result = pd.concat(total_list)
return result
다음과 같이 데이터와 backtesting에 활용할 기간, rebalancing 기간, 포트폴리오의 수를 input으로 받아 전체 기간에서의 backtesting을 통한 각 포트폴리오의 수익률을 values로 가지는 DataFrame을 반환받습니다.
5. Backtesting
portfolio_ret = period_split_std(data, 60, 3, 8)
portfolio_ret.tail()
| portfolio1 | portfolio2 | portfolio3 | portfolio4 | portfolio5 | portfolio6 | portfolio7 | portfolio8 | |
|---|---|---|---|---|---|---|---|---|
| 2015-12-31 | 1.071693 | 0.961979 | 0.931851 | 0.969705 | 0.967224 | 0.948853 | 0.992491 | 0.960513 |
| 2016-03-31 | 1.003132 | 1.066610 | 1.040075 | 0.948614 | 1.048135 | 1.104522 | 1.051418 | 1.156299 |
| 2016-06-30 | 0.935060 | 0.956624 | 0.978946 | 0.909576 | 0.956315 | 0.994503 | 0.959145 | 1.248704 |
| 2016-09-30 | 1.022513 | 0.990528 | 0.995827 | 1.052481 | 1.044531 | 0.999911 | 0.998524 | 0.982455 |
| 2016-12-31 | 0.986534 | 1.015902 | 0.959997 | 0.986215 | 0.912742 | 0.989903 | 0.995799 | 0.892104 |
다음과 같이 backtesting 기간 60개월, 3개월 마다 rebalancing, 8개의 포트폴리오의 수익률을 반환하는 DataFrame을 받습니다.
invest_df = np.cumprod(portfolio_ret)
invest_df.tail()
| portfolio1 | portfolio2 | portfolio3 | portfolio4 | portfolio5 | portfolio6 | portfolio7 | portfolio8 | |
|---|---|---|---|---|---|---|---|---|
| 2015-12-31 | 22.089027 | 15.323978 | 17.044369 | 11.456239 | 25.974302 | 15.543262 | 19.190994 | 9.313575 |
| 2016-03-31 | 22.158216 | 16.344703 | 17.727426 | 10.867547 | 27.224579 | 17.167881 | 20.177751 | 10.769276 |
| 2016-06-30 | 20.719269 | 15.635739 | 17.354186 | 9.884856 | 26.035282 | 17.073513 | 19.353394 | 13.447639 |
| 2016-09-30 | 21.185727 | 15.487638 | 17.281759 | 10.403620 | 27.194658 | 17.071992 | 19.324833 | 13.211694 |
| 2016-12-31 | 20.900433 | 15.733920 | 16.590433 | 10.260205 | 24.821714 | 16.899622 | 19.243650 | 11.786201 |
위에서 얻은 수익률을 np.cumprod()함수를 활용하여 누적수익률을 계산합니다.
def cum_plot(data, title):
data.index = pd.to_datetime(data.index, format="%Y%m")
plt.figure(figsize=(20,7))
plt.plot(data)
plt.title(title)
plt.axhline(color = 'k')
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_color('none')
ax.spines['left'].set_color('none')
ax.legend(data.columns.values)
plt.show()
데이터를 좀 더 보기 쉽게 plotting 해주는 function을 새로 구성해주면 결과를 그래프의 형태로 확인할 수 있습니다.
Conclustion
cum_plot(invest_df, "변동성 포트폴리오 누적 수익률(2000~2016)")
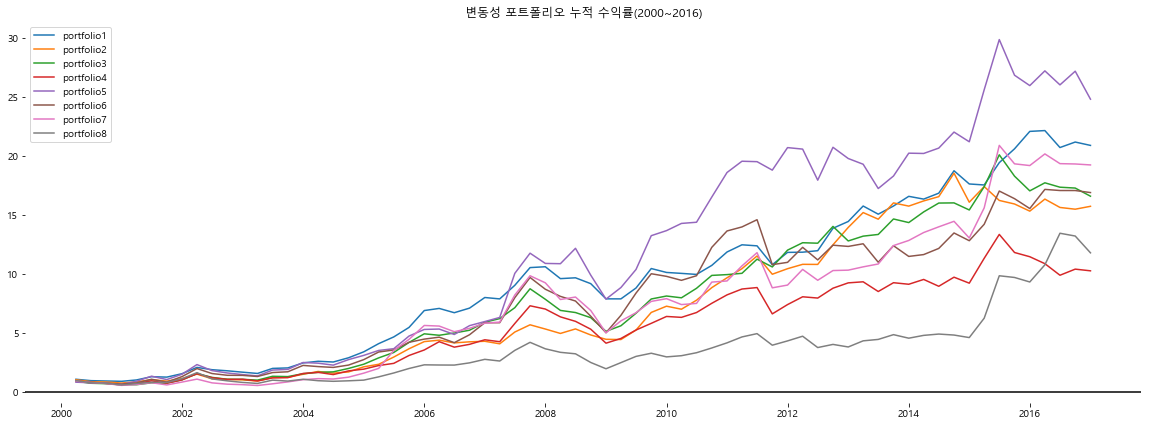
다음과 같이 일반적으로 생각하는 가장 높은 risk를 보유한 portfolio8의 경우에 오히려 장기적으로 보았을 경우 변동성의 비하여 낮은 수익률을 기록하는 저변동성 효과를 확인할 수 있습니다. 반대로 가장 낮은 변동성의 개별 주식들로 구성된 포트폴리오의 경우에는 장기적으로 높은 수준의 수익률을 기록하는 것을 확인할 수 있습니다.
대부분의 포트폴리오들이 risk가 낮은 장기적으로 높은 수익률을 확보하는 경향을 backtesting을 통해 확인할 수 있습니다.