[Smart Beta] Chapter 3. Size Effect - 소형주 효과
소형주 효과(Size Effect)
소형주 효과의 발견과 의미
Rolf W. Banz의 1981년 “The Relationship Between Market Value and Return of Common Stocks”
해당 논문을 통해 1926년-1980년 기간 중 NYSE에 상장된 종목들을 시가총액가중 기준으로 분류하여 수익률과 리스크를 측정한 결과, 시가총액이 큰 종목이 작은 종목의 리스크 대비 초과수익률이 존재한다.
이는 효율적 시장가설(Efficient Mkt Theory)에 반하는 실증적 발견으로 시장의 Anomaly 중 하나로 연구되기 시작함.
Fama-French의 3 Factor model에서도 Size Effect와 B/M은 시장의 체계적인 리스크(Systemical Risk)로 설명되지 않는 Factor로 바라봄.
각 지역별 SMB 팩터 누적 수익률(1990.7-2018.1)
데이터 불러오기 및 데이터 확인하기
pandas는 표 형식의 자료를 DataFrame 객체로 읽어오는 기능을 제공한다.
- pandas의 read_excel 함수를 이용하여 데이터를 불러온다.
- 불러온 데이터의 값을 확인하기 위해 데이터객체명.head() 혹은 .tail()을 이용하여 불러온 데이터를 확인한다.
import pandas as pd
import numpy as np
df = pd.read_excel('smb_cumreturn_data.xlsx', index_col = 0)
df.index = pd.to_datetime(df.index, format = '%Y%m')
print(df.head())
Global Global ex US Europe Japan Asia ex Japan
1990-07-01 0.77 2.77 0.48 6.01 -2.98
1990-08-01 -1.60 -0.92 -0.12 -4.98 2.99
1990-09-01 1.23 3.21 1.75 0.75 4.12
1990-10-01 -7.39 -8.98 -2.76 1.23 -5.04
1990-11-01 1.22 1.17 -2.75 -5.48 -1.62
데이터 연산하기
누적수익률 구하기
- DataFrame의 각 열(지역구분)에 담겨있는 월별 수익률의 누적수익률을 구한다. 객체명.cumprod() 함수를 이용하면 쉽게 구할 수 있다.
- cumprod() 함수의 결과 타입이 Series 이므로 이를 DataFrame 타입으로 변환해준다.
- 계산한 데이터의 값들을 확인한다.
df1 = (1 + df['Global']/100).cumprod() -1
df2 = (1 + df['Global ex US']/100).cumprod() -1
df3 = (1 + df['Europe']/100).cumprod() -1
df4 = (1 + df['Japan']/100).cumprod() -1
df5 = (1 + df['Asia ex Japan']/100).cumprod() -1
df6 = df1 - df2
frame = pd.Series.to_frame(df1)
frame['Global ex Us'] = df2
frame['Europe'] = df3
frame['Japan'] = df4
frame['Asia ex Japan'] = df5
frame['US'] = df6
frame.tail()
| Global | Global ex Us | Europe | Japan | Asia ex Japan | US | |
|---|---|---|---|---|---|---|
| 2017-10-01 | 0.048795 | 0.068222 | -0.065510 | 0.040166 | -0.599847 | -0.019427 |
| 2017-11-01 | 0.041663 | 0.068435 | -0.069248 | 0.040686 | -0.606610 | -0.026772 |
| 2017-12-01 | 0.051455 | 0.087453 | -0.054635 | 0.061396 | -0.602636 | -0.035999 |
| 2018-01-01 | 0.040204 | 0.089193 | -0.047072 | 0.078484 | -0.609431 | -0.048989 |
| 2018-02-01 | 0.048630 | 0.103135 | -0.035446 | 0.089700 | -0.611111 | -0.054505 |
그래프로 확인하기
지역별 SMB 팩터 누적수익률을 그래프로 시각화하여 비교하기
matplotlib을 이용하여 그래프를 그릴 수도 있으나 데이터를 보여줄 다양한 형태를 일일이, 비교적 많이 입력해주어야 한다. 반면 pandas를 이용하면 다양한 종류의 데이터를 한 그래프 안에 간단하게 담아낼 수 있다.
DataFrame.plot() 은 DataFrame 의 행과 열의 정보를 손쉽게 그래프로 나타내준다.
표의 사이즈, x축의 범위, y축의 범위를 설정해준다.
ax = frame.plot(figsize=(12,8))
ax.axhline(0, color='black',lw=0.8) #https://financedata.github.io/posts/matplotlib_hline_and_vline.html 참고(유용할듯..)
frame.index = pd.to_datetime(frame.index, format = 'Ym')
ax.set_ylim(-0.8, 0.2)
ax.spines['right'].set_color('none') # 박스없애기(오른쪽 선 지우기 = 색없음)
ax.spines['left'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_color('none')
ax.xaxis.set_ticks_position('none') # x축의 눈금 삭제(none) cf) left, right
ax
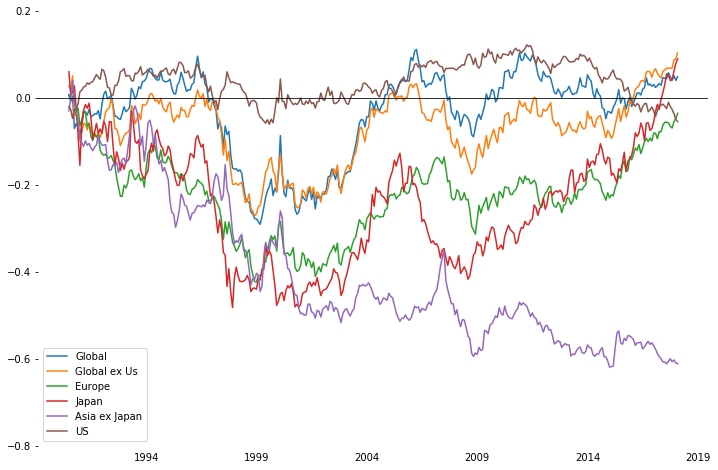
1990.7 부터 2018.1 기간동안에 대하여 각 지역별 SMB 팩터 검증 결과 Banz의 주장과 달리 소형주 효과의 존재 여부에 대해 의문을 갖게한다.
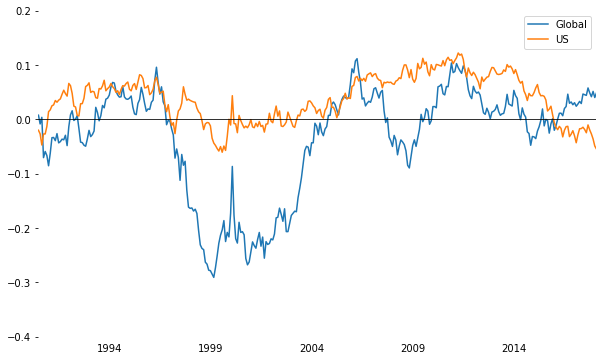
Global 과 US 지역의 비교
frame2 = pd.Series.to_frame(df1)
frame2['US'] = df6
frame2.head(3)
| Global | US | |
|---|---|---|
| 1990-07-01 | 0.007700 | -0.020000 |
| 1990-08-01 | -0.008423 | -0.026668 |
| 1990-09-01 | 0.003773 | -0.047158 |
ax1 = frame2.plot(figsize=(10,6))
ax1.axhline(0, color='black',lw=0.8)
ax1.set_xlim(pd.Timestamp('1990-07-01'), pd.Timestamp('2018-02-01'))
ax1.set_ylim(-0.4, 0.2)
ax1.spines['right'].set_color('none')
ax1.spines['left'].set_color('none')
ax1.spines['top'].set_color('none')
ax1.spines['bottom'].set_color('none')
ax1.xaxis.set_ticks_position('none')
ax1
소형 RMW - 대형 RMW 누적 수익률(1990-2018)
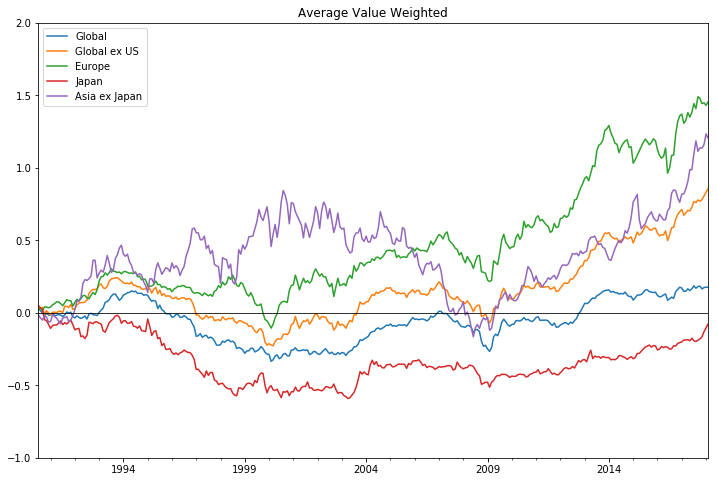
소형주 효과의 검증을 위해 ‘시가총액가중 기준’ 과 ‘동일가중 기준’ 포트폴리오에 대하여 누적 수익률을 분석한다.
A. 시가총액가중 기준
데이터 불러오기 및 데이터 확인하기
pandas는 표 형식의 자료를 DataFrame 객체로 읽어오는 기능을 제공한다.
- pandas의 read_excel 함수를 이용하여 데이터를 불러온다.
- 불러온 데이터의 값을 확인하기 위해 데이터객체명.head() 혹은 .tail()을 이용하여 불러온 데이터를 확인한다.
df_glo = pd.read_excel('시가총액가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=0, index_col=0)
df_exus = pd.read_excel('시가총액가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=1, index_col=0)
df_eu = pd.read_excel('시가총액가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=2, index_col=0)
df_jpn = pd.read_excel('시가총액가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=3, index_col=0)
df_exjpn = pd.read_excel('시가총액가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=4, index_col=0)
df_glo.head(3)
| SMALL LoOP | SMALL HiOP | BIG LoOP | BIG HiOP | |
|---|---|---|---|---|
| 1990-07-01 | 1.75 | 3.25 | 1.85 | 0.66 |
| 1990-08-01 | -11.10 | -11.95 | -10.25 | -9.84 |
| 1990-09-01 | -10.21 | -10.92 | -12.20 | -11.41 |
소형 RMW - 대형 RMW
d1 = (df_glo['SMALL HiOP'] - df_glo['SMALL LoOP']) - (df_glo['BIG HiOP'] - df_glo['BIG LoOP'])
d2 = (df_exus['SMALL HiOP'] - df_exus['SMALL LoOP']) - (df_exus['BIG HiOP'] - df_exus['BIG LoOP'])
d3 = (df_eu['SMALL HiOP'] - df_eu['SMALL LoOP']) - (df_eu['BIG HiOP'] - df_eu['BIG LoOP'])
d4 = (df_jpn['SMALL HiOP'] - df_jpn['SMALL LoOP']) - (df_jpn['BIG HiOP'] - df_jpn['BIG LoOP'])
d5 = (df_exjpn['SMALL HiOP'] - df_exjpn['SMALL LoOP']) - (df_exjpn['BIG HiOP'] - df_exjpn['BIG LoOP'])
print(d5.head())
print(d5.tail())
1990-07-01 -1.64
1990-08-01 -1.92
1990-09-01 -1.52
1990-10-01 3.23
1990-11-01 -1.15
dtype: float64
2017-10-01 1.16
2017-11-01 -0.10
2017-12-01 1.13
2018-01-01 3.43
2018-02-01 -1.30
dtype: float64
데이터 연산하기
지역별 누적 수익률 계산
d1 = (1 + d1/100).cumprod() - 1
d2 = (1 + d2/100).cumprod() - 1
d3 = (1 + d3/100).cumprod() - 1
d4 = (1 + d4/100).cumprod() - 1
d5 = (1 + d5/100).cumprod() - 1
d5.tail(3)
2017-12-01 1.160573
2018-01-01 1.234680
2018-02-01 1.205629
dtype: float64
계산된 데이터 정리
계산된 결과값의 type이 Series이므로 DataFrame 으로 정리해준다.
x = pd.DataFrame({'Global': d1,
'Global ex US': d2,
'Europe': d3,
'Japan': d4,
'Asia ex Japan': d5
})
x = x[['Global','Global ex US','Europe','Japan','Asia ex Japan']]
print(x.head())
print(x.tail())
Global Global ex US Europe Japan Asia ex Japan
1990-07-01 0.026900 0.026200 0.023800 0.049300 -0.016400
1990-08-01 0.013961 0.028252 0.031683 0.034505 -0.035285
1990-09-01 -0.001248 0.037404 0.014970 0.024781 -0.049949
1990-10-01 -0.021423 -0.011769 0.041765 -0.047774 -0.019262
1990-11-01 -0.002047 0.015605 0.039473 -0.053583 -0.030541
Global Global ex US Europe Japan Asia ex Japan
2017-10-01 0.183771 0.769602 1.478557 -0.179649 1.138570
2017-11-01 0.164949 0.781281 1.443114 -0.165129 1.136431
2017-12-01 0.174152 0.806932 1.449466 -0.130732 1.160573
2018-01-01 0.177322 0.831506 1.431340 -0.103959 1.234680
2018-02-01 0.176969 0.856231 1.455410 -0.076988 1.205629
그래프로 확인하기
소형주 효과를 반영한 RMW 지역별 누적수익률을 그래프로 시각화하여 비교하기
matplotlib을 이용하여 그래프를 그릴 수도 있으나 데이터를 보여줄 다양한 형태를 일일이, 비교적 많이 입력해주어야 한다. 반면 pandas를 이용하면 다양한 종류의 데이터를 한 그래프 안에 간단하게 담아낼 수 있다.
- DataFrame.plot() 은 DataFrame 의 행과 열의 정보를 손쉽게 그래프로 나타내준다.
- 표의 사이즈, x축의 범위, y축의 범위를 설정해준다.
ax2 = x.plot(figsize=(12,8))
ax2.set_xlim(pd.Timestamp('1990-07-01'), pd.Timestamp('2018-02-01'))
ax2.set_ylim(-1, 2)
ax2.axhline(0, color='black',lw=0.8)
ax2.set_title('Average Value Weighted')
ax2
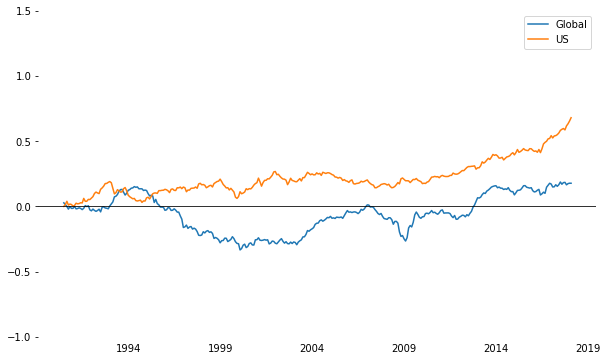
Global vs US
x1 = pd.DataFrame({'Global': d1,
'US': d2-d1
})
print(x1.head(2))
print(x1.tail(2))
Global US
1990-07-01 0.026900 -0.000700
1990-08-01 0.013961 0.014291
Global US
2018-01-01 0.177322 0.654183
2018-02-01 0.176969 0.679262
ax4 = x1.plot(figsize=(10,6))
ax4.axhline(0, color='black',lw=0.8)
# ax4.set_xlim(pd.Timestamp('1990'), pd.Timestamp('2018'))
ax4.set_ylim(-1, 1.5)
ax4.spines['right'].set_color('none')
ax4.spines['left'].set_color('none')
ax4.spines['top'].set_color('none')
ax4.spines['bottom'].set_color('none')
ax4.xaxis.set_ticks_position('none')
ax4
그래프로 확인하기2
matplotlib를 이용하여 설정 바꿔가며 그리기
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(12,8))
ax3 = fig.add_subplot(1,1,1)
ax3.plot(d1, label='Global')
ax3.plot(d2, label='Global ex US')
ax3.plot(d3, label='Europe')
ax3.plot(d4, label='Japan')
ax3.plot(d5, label='Asia ex Japan')
ax3.set_xlabel('Year')
ax3.set_ylabel('Cumulative return')
ax3.set_ylim(-1,2)
ax3.xaxis.set_ticks_position('none')
ax3.spines['right'].set_color('none')
ax3.spines['left'].set_color('none')
ax3.spines['top'].set_color('none')
ax3.spines['bottom'].set_color('none')
ax3.legend()
plt.title('Average Value Weighted')
plt.axhline(0, color='black',lw=0.5)
plt.show()

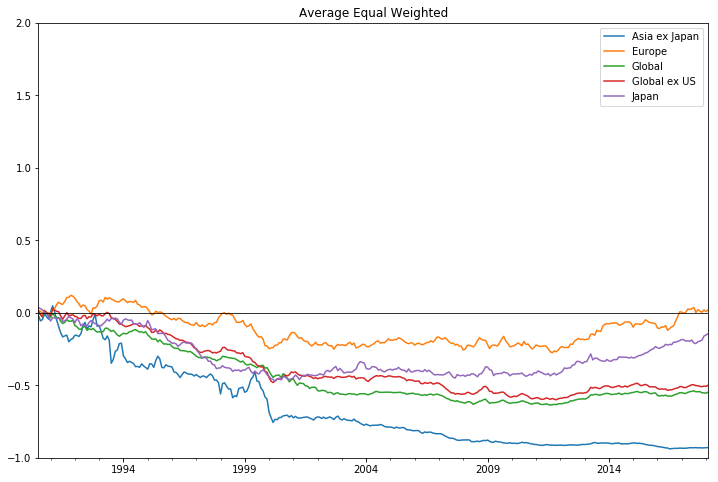
B. 동일가중기준
데이터 불러오기 및 데이터 확인하기
pandas는 표 형식의 자료를 DataFrame 객체로 읽어오는 기능을 제공한다.
- pandas의 read_excel 함수를 이용하여 데이터를 불러온다.
- 불러온 데이터의 값을 확인하기 위해 데이터객체명.head() 혹은 .tail()을 이용하여 불러온 데이터를 확인한다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df_glo = pd.read_excel('동일가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=0, index_col=0)
df_exus = pd.read_excel('동일가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=1, index_col=0)
df_eu = pd.read_excel('동일가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=2, index_col=0)
df_jpn = pd.read_excel('동일가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=3, index_col=0)
df_exjpn = pd.read_excel('동일가중 기준 소형 RMW- 대형 RMW.xlsx',sheet_name=4, index_col=0)
print(df_glo.head(2))
print(df_glo.tail(2))
SMALL LoOP SMALL HiOP BIG LoOP BIG HiOP
1990-07-01 1.94 3.32 2.36 2.82
1990-08-01 -7.85 -10.03 -11.61 -11.78
SMALL LoOP SMALL HiOP BIG LoOP BIG HiOP
2018-01-01 6.51 5.38 4.99 4.43
2018-02-01 -4.05 -2.14 -3.86 -3.71
소형 RMW - 대형 RMW
d1 = (df_glo['SMALL HiOP'] - df_glo['SMALL LoOP']) - (df_glo['BIG HiOP'] - df_glo['BIG LoOP'])
d2 = (df_exus['SMALL HiOP'] - df_exus['SMALL LoOP']) - (df_exus['BIG HiOP'] - df_exus['BIG LoOP'])
d3 = (df_eu['SMALL HiOP'] - df_eu['SMALL LoOP']) - (df_eu['BIG HiOP'] - df_eu['BIG LoOP'])
d4 = (df_jpn['SMALL HiOP'] - df_jpn['SMALL LoOP']) - (df_jpn['BIG HiOP'] - df_jpn['BIG LoOP'])
d5 = (df_exjpn['SMALL HiOP'] - df_exjpn['SMALL LoOP']) - (df_exjpn['BIG HiOP'] - df_exjpn['BIG LoOP'])
print(d1.head(2))
print(d1.tail(2))
1990-07-01 0.92
1990-08-01 -2.01
dtype: float64
2018-01-01 -0.57
2018-02-01 1.76
dtype: float64
소형 RMW - 대형 RMW 누적 수익률 연산
d1 = (1 + d1/100).cumprod() - 1
d2 = (1 + d2/100).cumprod() - 1
d3 = (1 + d3/100).cumprod() - 1
d4 = (1 + d4/100).cumprod() - 1
d5 = (1 + d5/100).cumprod() - 1
print(d1.head(2))
print(d1.tail(2))
1990-07-01 0.009200
1990-08-01 -0.011085
dtype: float64
2018-01-01 -0.554678
2018-02-01 -0.546841
dtype: float64
연산된 데이터 정리하기
x = pd.DataFrame({'Global': d1,
'Global ex US': d2,
'Europe': d3,
'Japan': d4,
'Asia ex Japan': d5
})
x = x[['Global','Global ex US','Europe', 'Japan','Asia ex Japan']]
print(x.head())
print(x.tail())
Global Global ex US Europe Japan Asia ex Japan
1990-07-01 0.009200 0.011200 0.016700 0.034900 -0.019800
1990-08-01 -0.011085 -0.012867 0.011108 0.028898 -0.055675
1990-09-01 -0.031358 -0.024712 -0.005171 0.020564 -0.045854
1990-10-01 -0.000071 0.014007 0.018208 0.003520 -0.005780
1990-11-01 -0.007470 0.002041 0.003749 -0.004006 -0.026559
Global Global ex US Europe Japan Asia ex Japan
2017-10-01 -0.543415 -0.506970 0.011607 -0.195181 -0.930436
2017-11-01 -0.551542 -0.509830 0.004020 -0.188259 -0.932099
2017-12-01 -0.552125 -0.504928 0.020285 -0.159929 -0.931447
2018-01-01 -0.554678 -0.507206 0.008042 -0.152705 -0.930624
2018-02-01 -0.546841 -0.499025 0.021550 -0.144740 -0.929473
ax2 = x.plot(figsize=(12,8))
ax2.set_xlim(pd.Timestamp('1990-07'), pd.Timestamp('2018-02'))
ax2.set_ylim(-1, 2)
ax2.axhline(0, color='black',lw=0.8)
ax2.set_title('Average Equal Weighted')
ax2
소형주 효과를 반영한 시가총액가중기준 소형 CMA - 대형 CMA 누적수익률
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data_glo = pd.read_excel('시가총액가중기준CMA.xlsx', sheet_name=0,index_col=0)
data_exus = pd.read_excel('시가총액가중기준CMA.xlsx', sheet_name=1,index_col=0)
data_eu = pd.read_excel('시가총액가중기준CMA.xlsx', sheet_name=2,index_col=0)
data_jpn = pd.read_excel('시가총액가중기준CMA.xlsx', sheet_name=3,index_col=0)
data_exjpn = pd.read_excel('시가총액가중기준CMA.xlsx', sheet_name=4,index_col=0)
print(data_glo.head(3))
print(data_exus.head(3))
SMALL LoINV ME1 INV2 SMALL HiINV BIG LoINV ME2 INV2 BIG HiINV
1990-07-01 2.26 1.98 1.06 2.41 1.01 0.47
1990-08-01 -10.96 -10.78 -12.13 -9.22 -10.11 -10.01
1990-09-01 -9.86 -9.60 -10.80 -9.83 -10.75 -13.15
SMALL LoINV ME1 INV2 SMALL HiINV BIG LoINV ME2 INV2 BIG HiINV
1990-07-01 4.98 4.81 4.89 2.94 1.92 1.81
1990-08-01 -10.85 -10.78 -11.29 -10.37 -10.44 -9.87
1990-09-01 -10.73 -10.76 -11.34 -13.55 -14.14 -14.55
print(data_glo.tail(3))
SMALL LoINV ME1 INV2 SMALL HiINV BIG LoINV ME2 INV2 BIG HiINV
2017-12-01 2.78 1.57 2.37 2.26 1.04 1.00
2018-01-01 4.60 3.44 4.27 5.06 4.91 6.35
2018-02-01 -3.58 -3.53 -2.89 -5.36 -4.16 -2.41
d1 = (data_glo['SMALL LoINV']-data_glo['SMALL HiINV']) - (data_glo['BIG LoINV']-data_glo['BIG HiINV'])
d2 = (data_exus['SMALL LoINV']-data_exus['SMALL HiINV']) - (data_exus['BIG LoINV']-data_exus['BIG HiINV'])
d3 = (data_eu['SMALL LoINV']-data_eu['SMALL HiINV']) - (data_eu['BIG LoINV']-data_eu['BIG HiINV'])
d4 = (data_jpn['SMALL LoINV']-data_jpn['SMALL HiINV']) - (data_jpn['BIG LoINV']-data_jpn['BIG HiINV'])
d5 = (data_exjpn['SMALL LoINV']-data_exjpn['SMALL HiINV']) - (data_exjpn['BIG LoINV']-data_exjpn['BIG HiINV'])
print(d1.head(2))
print(d1.tail(2))
1990-07-01 -0.74
1990-08-01 0.38
dtype: float64
2018-01-01 1.62
2018-02-01 2.26
dtype: float64
d1 = (1 + d1/100).cumprod() - 1
d2 = (1 + d2/100).cumprod() - 1
d3 = (1 + d3/100).cumprod() - 1
d4 = (1 + d4/100).cumprod() - 1
d5 = (1 + d5/100).cumprod() - 1
print(d1.head(2))
print(d1.tail(2))
1990-07-01 -0.007400
1990-08-01 -0.003628
dtype: float64
2018-01-01 0.759363
2018-02-01 0.799125
dtype: float64
x = pd.DataFrame({'Global': d1,
'Global ex US': d2,
'Europe': d3,
'Japan': d4,
'Asia ex Japan': d5
})
x = x[['Global', 'Global ex US', 'Europe', 'Japan', 'Asia ex Japan']]
print(x.head())
print(x.tail())
Global Global ex US Europe Japan Asia ex Japan
1990-07-01 -0.007400 -0.010400 0.000700 -0.009300 -0.002900
1990-08-01 -0.003628 -0.001098 -0.009507 0.024384 -0.011674
1990-09-01 -0.027342 -0.004993 -0.013073 0.032784 -0.035691
1990-10-01 -0.013044 -0.011262 -0.008730 -0.058308 -0.000397
1990-11-01 -0.031105 -0.007010 -0.006351 -0.012071 0.003401
Global Global ex US Europe Japan Asia ex Japan
2017-10-01 0.775634 0.433035 0.623264 -0.165711 1.161845
2017-11-01 0.746158 0.410393 0.594370 -0.161122 1.219567
2017-12-01 0.731316 0.394738 0.594530 -0.178990 1.206471
2018-01-01 0.759363 0.377024 0.571090 -0.178826 1.208016
2018-02-01 0.799125 0.378126 0.562763 -0.201983 1.259683
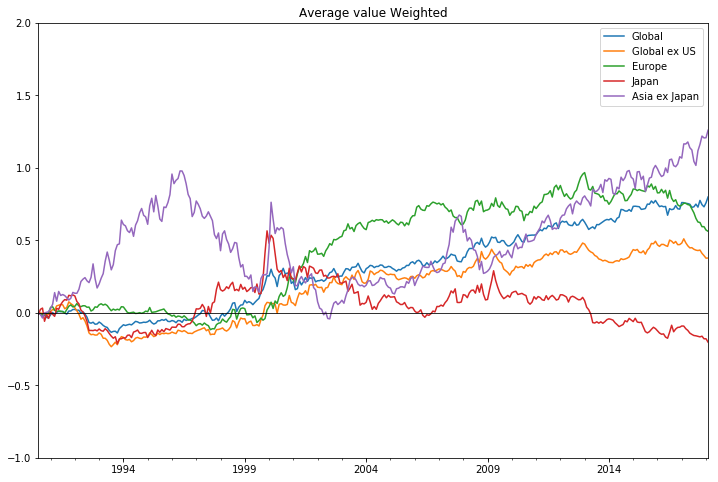
ax = x.plot(figsize=(12,8))
ax.set_xlim(pd.Timestamp('1990-07'), pd.Timestamp('2018-02'))
ax.set_ylim(-1, 2)
ax.axhline(0, color='black',lw=0.8)
ax.set_title('Average value Weighted')
ax
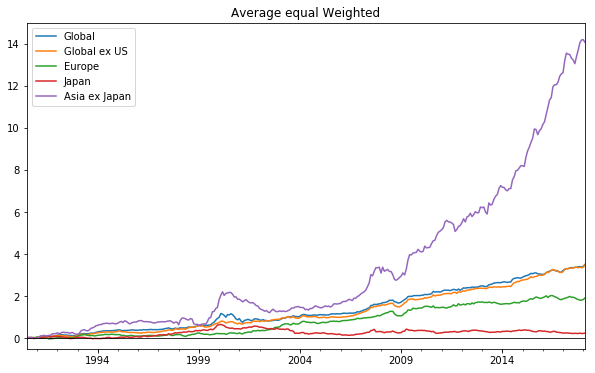
소형주 효과를 반영한 동일가중기준 소형 CMA - 대형 CMA 누적수익률
data2_glo = pd.read_excel('동일가중기준CMA.xlsx', sheet_name=0,index_col=0)
data2_exus = pd.read_excel('동일가중기준CMA.xlsx', sheet_name=1,index_col=0)
data2_eu = pd.read_excel('동일가중기준CMA.xlsx', sheet_name=2,index_col=0)
data2_jpn = pd.read_excel('동일가중기준CMA.xlsx', sheet_name=3,index_col=0)
data2_exjpn = pd.read_excel('동일가중기준CMA.xlsx', sheet_name=4,index_col=0)
print(data2_glo.head(2))
print(data2_glo.tail(2))
SMALL LoINV ME1 INV2 SMALL HiINV BIG LoINV ME2 INV2 BIG HiINV
1990-07-01 2.16 1.94 1.23 2.98 2.32 1.91
1990-08-01 -7.40 -9.30 -9.97 -11.40 -11.47 -11.96
SMALL LoINV ME1 INV2 SMALL HiINV BIG LoINV ME2 INV2 BIG HiINV
2018-01-01 7.11 4.74 6.15 4.97 4.47 4.67
2018-02-01 -3.64 -3.08 -4.01 -4.63 -3.97 -2.86
data1 = (data2_glo['SMALL LoINV']-data2_glo['SMALL HiINV']) - (data2_glo['BIG LoINV']-data2_glo['BIG HiINV'])
data2 = (data2_exus['SMALL LoINV']-data2_exus['SMALL HiINV']) - (data2_exus['BIG LoINV']-data2_exus['BIG HiINV'])
data3 = (data2_eu['SMALL LoINV']-data2_eu['SMALL HiINV']) - (data2_eu['BIG LoINV']-data2_eu['BIG HiINV'])
data4 = (data2_jpn['SMALL LoINV']-data2_jpn['SMALL HiINV']) - (data2_jpn['BIG LoINV']-data2_jpn['BIG HiINV'])
data5 = (data2_exjpn['SMALL LoINV']-data2_exjpn['SMALL HiINV']) - (data2_exjpn['BIG LoINV']-data2_exjpn['BIG HiINV'])
data1 = (1 + data1/100).cumprod() - 1
data2 = (1 + data2/100).cumprod() - 1
data3 = (1 + data3/100).cumprod() - 1
data4 = (1 + data4/100).cumprod() - 1
data5 = (1 + data5/100).cumprod() - 1
y = pd.DataFrame({'Global': data1,
'Global ex US': data2,
'Europe': data3,
'Japan': data4,
'Asia ex Japan': data5
})
y = y[['Global', 'Global ex US', 'Europe', 'Japan', 'Asia ex Japan']]
print(y.head(2))
print(y.tail(2))
Global Global ex US Europe Japan Asia ex Japan
1990-07-01 -0.001400 -0.00210 -0.003300 -0.010900 0.022000
1990-08-01 0.018672 0.02644 0.010654 0.013234 0.042644
Global Global ex US Europe Japan Asia ex Japan
2018-01-01 3.413879 3.379474 1.838120 0.233228 14.190292
2018-02-01 3.508336 3.478012 1.914465 0.240751 14.065732
ax1 = y.plot(figsize=(10,6))
ax1.set_xlim(pd.datetime(1990,7,1), pd.datetime(2018,2,1))
ax1.set_ylim(-0.5, 15)
ax1.axhline(0, color='black',lw=0.8)
ax1.set_title('Average equal Weighted')
ax1